Scaling with NuoDB
I know, there was a small gap between NuoDB related posts. I was little bit busy. But I’m now going to change it. In today’s post we’ll try to scale our chorus both in transactions and I/O throughput.
As you maybe remember from the first post, in NuoDB you have transaction and archive nodes. More transaction nodes means more queries/commands processed (yes, for badly designed application there might be other bottlenecks). And similarly with archive nodes that are in charge of persisting data to some storage and fetching data for mainly transaction nodes.
Simple. You already know how to start the agent and nodes from previous posts, but I think you will agree, that typing parameters on command line and keeping track what’s running where (and whether it’s running) is hard. This is where the NuoDB Console enters the game. It’s a simple application that shows you how your NuoDB world is looking.
Have a look at this picture (yeah, test machine is Windows XP 😎).

You can see there’s one broker running on my ’test’ machine. There are two choruses, with bunch of nodes. In this picture everything is on same machine, but in real environment you would probably have it across more machine. In ’test’ chorus is one archive node being started (the grayed one), currently not 100% ready and in ’test2’ chorus there is on the other hand some problem with one transaction node. For any problem you can check the log to see what’s wrong. From the same interface, using wizard, add nodes. Better than typing the commands again and again.
Computers running agents are being discovered automatically, but you can always add some manually if you know address, port and of course password.
This a great tool to start playing what happens when you kill (forcibly, that’s valid scenarios) some node and whether the chorus survives and all data are safe. My favorite scenario is one transaction node, two archive. Kill one archive node and continue inserting/querying data. Bring killed one back online and kill the other one. If you’re slow, the data will be synchronized, if not you’re screwed. 😃 BTW insert into table select * from table works so you can easily generated big results and long running commands.
And if I’m talking about playing, there’s also one program, that’s great for playing and seeing what’s going on. In samples\flights you can find application that allows you to put load to your setup. The bottom line is that you can play with number of clients (threads), also percent of updates and reconnect timeout. On the other hand in console you can try adding and removing nodes and see the system throughput. Whether it scales properly or whether you have some bottleneck there.

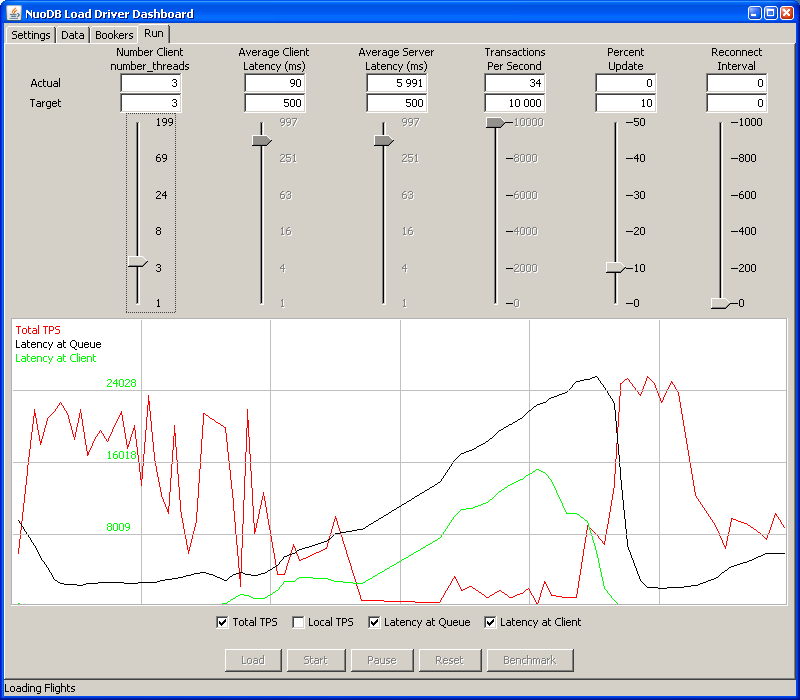
Wanna have more computing power? Add more machines with transaction nodes. Wanna be sure your data are safe in case of storage failure? Add more archive nodes. Also take into account, that each archive node holds complete data, not only some slices. So you should have enough free space available.
In next post we’ll deploy NuoDB into cloud (AWS) and use Amazon S3 as a storage for archive nodes (and as S3 in virtually unlimited, you don’t have to care about free space as mentioned above). Maybe I’ll also try flights demo in some medium size setup. 😉
